Redes de hoy
La industria de TI está en constante cambio y evolución. A medida que pasa el tiempo, hay un número cada vez mayor de tecnologías que ejercen presión sobre la red. Se forman nuevos paradigmas a medida que otros se alejan. Se están desarrollando y adoptando nuevos avances en el ámbito de las redes. Estos avances se están desarrollando para proporcionar innovación más rápida y la capacidad de adoptar tecnologías relevantes de una manera simplificada.
Esto requiere la necesidad de más inteligencia y la capacidad de aprovechar los datos de entornos conectados y distribuidos, como el campus, la sucursal, el Data Center y la WAN. Hacerlo permite el uso de datos de formas interesantes y más poderosas que nunca antes. Algunos de los avances que impulsan estos resultados son
- Artificial intelligence (AI)
- Machine learning (ML)
- Cloud services
- Virtualization
- Internet of Things (IoT)
La afluencia de estas tecnologías está ejerciendo presión sobre el personal de operaciones de TI. Esta tensión viene en la forma de requerir una planificación más sólida, casos de uso relevantes acordados y materiales de viaje de adopción detallados para facilitar el consumo. Todos estos requisitos se están volviendo críticos para el éxito. Otra área de importancia es el despliegue y
las operaciones diarias de estas tecnologías, así como también cómo encajan dentro del entorno de red. La interrupción de las operaciones típicas es más inminente con respecto a algunas de estas tecnologías y cómo serán consumidas por el negocio. Se están adoptando otros avances tecnológicos para reducir el costo de las operaciones y la complejidad. Cada red, hasta cierto punto, tiene una complejidad inherente. Tener herramientas que puedan ayudar a gestionar esta complejidad se está convirtiendo en una necesidad en estos días.
La automatización es algo por lo que luchan muchos en la industria de TI, porque las redes de hoy en día son cada vez más complicadas. A menudo, las organizaciones operan con un personal de TI escaso y un presupuesto de TI fijo o en disminución, y se esfuerzan por encontrar formas de aumentar el rendimiento de lo que la red puede hacer por el negocio. Otro impulsor para la adopción de estas tecnologías es mejorar la experiencia general del usuario dentro del entorno. Esto incluye permitir que los usuarios tengan la flexibilidad y la capacidad de acceder a cualquier aplicación crítica para el negocio desde cualquier lugar de la red y garantizar que tengan una experiencia excepcional al hacerlo. Además de mejorar la experiencia del usuario, el personal de operaciones de TI está buscando formas de simplificar las operaciones de la red.
Hay muchos riesgos inherentes asociados con la configuración manual de redes. Existe el riesgo de no poder moverse lo suficientemente rápido al implementar nuevas aplicaciones o servicios en la red. El riesgo también podría verse como configuraciones incorrectas que podrían causar una interrupción o un rendimiento de red subóptimo, lo que afectaría las operaciones comerciales y podría causar repercusiones financieras. Finalmente, existe el riesgo de que la propia empresa dependa de la red para algunos servicios críticos para la empresa y que estos no estén disponibles debido a que el personal de operaciones de TI no puede mantenerse al día con la demanda de la empresa desde una perspectiva de escala. . Según una encuesta del Centro de asistencia técnica (TAC) de Cisco realizada en 2016, el 95 % de los clientes de Cisco realizan tareas de configuración e implementación manualmente en sus redes. La encuesta también indicó que el 70 por ciento de los casos TAC creados están relacionados con configuraciones incorrectas. Esto significa que los errores tipográficos o los comandos utilizados incorrectamente son los culpables de la mayoría de los problemas observados en el entorno de red. Aquí es donde brilla la automatización. Tener la capacidad de significar la intención del cambio que debe realizarse, como implementar calidad de servicio (QoS) en la red y luego hacer que la red la configure automáticamente de manera adecuada, es un excelente ejemplo de automatización. Esto logra configurar servicios o características con gran velocidad y es de gran valor para el negocio. Simplificar las operaciones y reducir el error humano en última instancia reduce el riesgo.
Una analogía simple para la automatización de redes sería pensar en un automóvil. La razón por la que la mayoría de la gente usa un automóvil es para lograr un resultado específico deseado. En este caso, sería ir del punto A al punto B. Un automóvil funciona como un sistema holístico, no como una colección de partes que componen ese sistema, como se muestra en la Figura Por ejemplo, el tablero de instrumentos proporciona al conductor toda la información necesaria sobre cómo está funcionando el vehículo y el estado actual del mismo. Cuando el conductor quiere utilizar el vehículo, se requieren ciertos pasos operativos para hacerlo. El conductor simplemente indica la intención de conducir el automóvil al ponerlo en marcha y usar el sistema para ir del punto A al punto B.

¿Por qué no se pueden pensar las redes de la misma manera? Pensar en una red como una colección de dispositivos, como Routers, Switches y componentes inalámbricos, es lo que la industria de TI viene haciendo desde hace más de 30 años. El cambio de mentalidad para ver la red como un sistema holístico es un concepto más reciente que surge del advenimiento de los controladores de red: la separación de funciones y funciones entre sí. La descripción más común de esto es separar el plano de control del plano de datos. Tener un controlador que se asienta sobre el resto de los dispositivos, por así decirlo, brinda la ventaja de dar un paso atrás y operar la red como un todo desde un punto de administración centralizado. Esto es similar a operar un automóvil desde el asiento del conductor versus tratar de manejar el automóvil desde todas las piezas y componentes de los que se deriva. Para poner esto en términos más familiares, piense en la interfaz de línea de comandos (CLI). La CLI no está diseñada para realizar cambios de configuración a gran escala en varios dispositivos al mismo tiempo. Los métodos tradicionales de administración y mantenimiento de la red no son suficientes para mantenerse al día con el ritmo y las demandas de las redes actuales. El personal de operaciones debe poder moverse más rápido y simplificar todas las operaciones y configuraciones que tradicionalmente han entrado en red. Las capacidades de controlador y redes definidas por software (SDN) se están convirtiendo en áreas de enfoque en la industria y están evolucionando hasta un punto en el que pueden abordar los desafíos que enfrentan los equipos de operaciones de TI. Los controladores ofrecen la capacidad de gestionar la red como un sistema, lo que significa que la gestión de políticas puede automatizarse y abstraerse. Esto proporciona la capacidad de admitir cambios de políticas dinámicos en comparación con su predecesor de cambios manuales de políticas y configuraciones dispositivo por dispositivo cuando algo requiere un cambio dentro del entorno.
Tendencias empresariales y de TI comunes
La infraestructura de red tradicional se implementó cuando el perímetro de seguridad estaba bien definido. La mayoría de las aplicaciones tenían poco ancho de banda y la mayoría del contenido y las aplicaciones residían en centros de datos corporativos centralizados. Hoy en día, las empresas tienen requisitos muy diferentes. Las aplicaciones de gran ancho de banda, en tiempo real y de big data están impulsando la capacidad
límites de la red. En algunos casos, la mayor parte del tráfico se destina a Internet oa la nube pública, y el perímetro de seguridad que existía en el pasado está desapareciendo rápidamente. Esto se debe al aumento en el uso de dispositivos propios (BYOD), computación en la nube e IoT. Las desventajas y los riesgos de permanecer en el statu quo son significativos, y la innovación tecnológica no ha logrado abordar el problema de manera integral. Ha habido un gran aumento en el uso de ofertas de software como servicio (SaaS) e infraestructura como servicio (IaaS). Parece
como si cada día más aplicaciones se trasladaran a la nube. La adopción de soluciones como Microsoft Office 365, Google Apps, Salesforce.com (SFDC) y otras aplicaciones comerciales y de productividad basadas en SaaS está ejerciendo presión sobre la red. Esto incluye mantener las aplicaciones funcionando al máximo de su capacidad para garantizar que los usuarios tengan la mejor experiencia posible. La siguiente lista contiene algunas de las tendencias más comunes que ocurren en la industria de TI:
- Las aplicaciones se están trasladando a la nube (privada y pública).
- Los dispositivos móviles, BYOD y el acceso de invitados están sobrecargando al personal de TI.
- Las aplicaciones de gran ancho de banda ejercen presión sobre la red.
- La primera conectividad inalámbrica se está convirtiendo en la nueva normalidad.
- La demanda de seguridad y segmentación en todas partes dificulta las operaciones manuales.
- Los dispositivos IoT a menudo requieren acceso a la red de TI
La cantidad de dispositivos móviles en el campus y en entornos remotos que acceden a estas aplicaciones e Internet como resultado de BYOD y los servicios para invitados está aumentando rápidamente. La carga adicional de tráfico resultante de todos estos dispositivos, así como tendencias como IoT, ejercen una presión adicional sobre la red, especialmente en la LAN inalámbrica. La convergencia de servicios de voz y datos fue una transición importante. Sin embargo, cuando se trata de video, las redes actuales no solo deben tener en cuenta el manejo optimizado de QoS para aplicaciones de video, sino que también deben abordar las aplicaciones sensibles a la latencia y de gran ancho de banda que demandan los usuarios. Tradicionalmente, admitir estas tecnologías no era fácil y su implementación requería muchas configuraciones manuales antes de la implementación. Esto también condujo a una complejidad adicional en el entorno de red.
Con las tendencias comerciales y de TI cubiertas hasta ahora todavía en mente, es importante traducir estas tendencias en desafíos reales que enfrentan las organizaciones y ponerlas en la lengua vernácula de TI. Como se mencionó anteriormente, la red está enfrentando una presión como nunca antes. Esto está obligando a los equipos de TI a buscar formas de aliviar esa presión. Las organizaciones también están buscando formas de mejorar la experiencia general del usuario y de la aplicación con lo que poseen actualmente y, al mismo tiempo, reducir los costos. La falta de control sobre la visibilidad y el rendimiento de las aplicaciones, y mantenerse al día con la superficie de ataque de seguridad en constante crecimiento también contribuyen a que las organizaciones busquen una mejor manera de avanzar. Además, los silos organizacionales han causado que muchas organizaciones no puedan lograr los beneficios de algunas de estas nuevas tecnologías. Es necesario romper los silos para trabajar hacia un objetivo común para el negocio en su conjunto para que el negocio aproveche al máximo lo que algunos de estos avances definidos por software tienen para ofrecer.
Beneficios comunes deseados
Esta sección cubre algunos de los beneficios más comunes que las organizaciones buscan en su red de campus. Diseñar e implementar la red de campus de próxima generación se trata de aprovechar algunos beneficios muy útiles y el impacto que tienen en el entorno de la red y la experiencia general del usuario. Cada uno de los beneficios discutidos se enumeran aquí:
- Priorice y asegure el tráfico con control granular
- Reducir los costos y reducir la complejidad operativa
- Simplifique la solución de problemas con el análisis de causa raíz
- Proporcionar una experiencia de usuario uniforme y de alta calidad
- Implementar seguridad y segmentación de extremo a extremo
- Implementar dispositivos más rápido
Las redes de hoy no pueden escalar a la velocidad necesaria para abordar las necesidades cambiantes que requieren las organizaciones. Las redes centradas en hardware son tradicionalmente más caras y tienen una capacidad fija. También son más difíciles de admitir debido al enfoque de configuración caja por caja, las herramientas de administración en silos y la falta de aprovisionamiento automatizado. Las políticas conflictivas entre dominios y las diferentes configuraciones entre servicios hacen que las redes actuales sean inflexibles, estáticas, caras y engorrosas de mantener. Esto lleva a que la red sea más propensa a errores de configuración y vulnerabilidades de seguridad. Es importante pasar de una arquitectura centrada en la conectividad a una infraestructura centrada en aplicaciones o servicios que se centre en la experiencia del usuario y la simplicidad.
La solución necesaria para dar soporte a las empresas habilitadas para la nube de hoy en día debe ser completa e integral. Debe basarse en el enfoque definido por software mencionado anteriormente aprovechando el concepto de controlador. La solución también debe incluir un sólido conjunto de capacidades que reduzca los costos y la complejidad y promueva la continuidad del negocio y la innovación rápida. Estas capacidades deben incluir la separación del plano de gestión, el plano de control y el plano de datos, lo que proporciona más capacidades de escalamiento horizontal y la seguridad de saber dónde están los datos en todo momento.
La solución debe proporcionar varios modelos de consumo, como que algunos componentes se alojen en la nube y algunos componentes se administren en las instalaciones, con redundancia completa entre los dos. La solución también debe proporcionar un conjunto completo de herramientas de resolución de problemas y visibilidad de la red a las que se pueda acceder desde un solo lugar. Tener este tipo de solución ayudaría a proporcionar los siguientes resultados comerciales y casos de uso:
- Implementación de dispositivos más rápida sin interacción operativa
- Segmentación completa de la red de extremo a extremo para mejorar la seguridad y la privacidad
- Mayor rendimiento de la LAN
- Movilidad de host perfecta
- Mejor experiencia de usuario
Todas las cosas mencionadas hasta ahora son fundamentales en términos de lo que exigen las organizaciones para impulsar su red a convertirse en un activo que realmente diferencie a las organizaciones de sus pares de la industria. Muchas organizaciones confían en que la red funcione de la mejor manera para proporcionar valor y diferenciación competitiva para que sus organizaciones puedan sobresalir.
Esto es lo que está impulsando a esta industria a este tipo de tecnologías. Esta confianza también es la razón por la cual la industria ha aumentado la velocidad de adopción e implementación de estas soluciones.
Consideraciones de diseño de alto nivel
Teniendo en cuenta la complejidad de la mayoría de las redes que existen hoy en día, se pueden clasificar en un par de categorías, como redundantes y no redundantes. Típicamente,
la redundancia conduce a una mayor complejidad. A menudo, las redes más simples no planifican fallas o cortes y suelen ser diseños de alojamiento único con múltiples puntos únicos de falla. Las redes pueden contener diferentes aspectos de la redundancia. Cuando se habla estrictamente de la parte LAN del campus del entorno, puede incluir enlaces, controladores, Switches y puntos de acceso redundantes. La siguiente tabla enumera algunas de las técnicas comunes que se introducen cuando se trata de redundancia.
| Links Redundantes | Dispositivos Redundantes |
| Distancia Administrativa | Redistribución |
| Ingeniería de Trafico | Prevención de Loops |
| Selección de Ruta Preferida | Selección de la Ruta Preferida |
| Sumarizacion de Prefijos | Filtrado Avanzado |
| Filtrado |
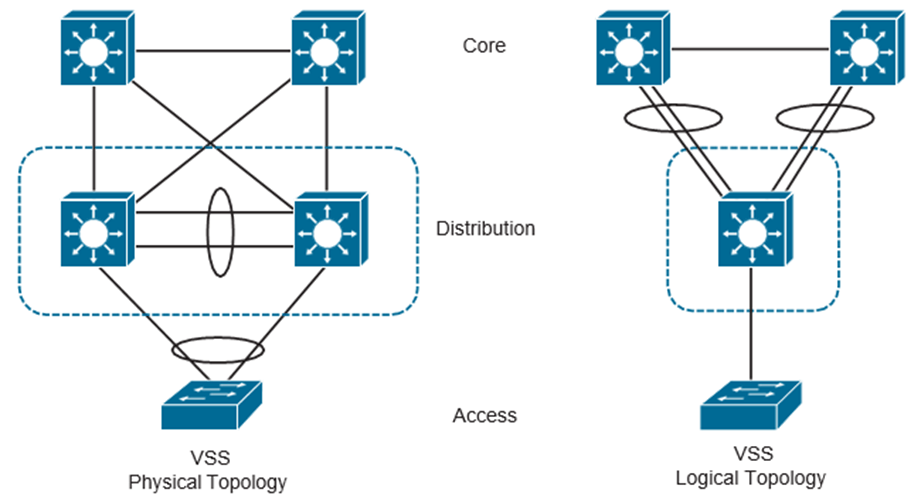
Hay muchas opciones de redundancia disponibles, como enlaces redundantes, dispositivos redundantes, EtherChannel, etc. A menudo es útil tener una idea de cómo se ven algunas de estas tecnologías de redundancia. Una de estas tecnologías es Cisco Virtual Switching System (VSS), que une los Switches para que se vean y actúen como un único conmutador. Esto ayuda a poner en contexto cómo será necesario configurar y administrar la red para admitir este tipo de opciones de redundancia. Los siguientes son algunos de los beneficios de la tecnología VSS:
- Simplifica las operaciones
- Impulsa la comunicación continua
- Maximiza la utilización del ancho de banda
- Reduce la latencia
La redundancia puede tomar muchas formas diferentes. VSS se utiliza para mucho más que redundancia. Ayuda con ciertos escenarios en el diseño de un campus, como eliminar la necesidad de VLAN ampliadas y bucles en la red. La siguiente Figura muestra un ejemplo de un entorno de campus antes y después de VSS y describe la simplificación de la topología.
Aparte de la complejidad asociada con la redundancia, hay muchos otros aspectos de la red que causan complejidad dentro de un entorno de red. Algunos de estos aspectos pueden incluir cosas como asegurar la red para protegerla de comportamientos maliciosos, aprovechar la segmentación de la red para mantener los tipos de tráfico separados por razones de cumplimiento o gobernanza, e incluso implementar QoS para garantizar un rendimiento óptimo de la aplicación y aumentar la calidad de los usuarios. experiencia. Lo que complica aún más la red es tener que configurar manualmente estas opciones. Las redes de hoy son demasiado rígidas y necesitan evolucionar. La industria está pasando de la era de los modelos de entrega de red centrados en la conectividad a una era de transformación digital. Se requiere un cambio para hacer la transición a un modelo de transformación digital. El cambio es de opciones centradas en hardware y dispositivos a soluciones abiertas, extensibles, impulsadas por software, programables y habilitadas para la nube. La Figura siguiente representa la transición en un resumen simple. Confiar más en la automatización para manejar las tareas operativas diarias y recuperar tiempo para enfocarse en cómo hacer que la red brinde valor al negocio es crucial para muchas organizaciones. Esto se entrega a través de capacidades basadas en políticas, automatizadas y de optimización automática. Esto proporciona una garantía de servicio automatizada de bucle cerrado que permite al personal de operaciones de red pasar de una naturaleza reactiva a un enfoque más proactivo y predictivo. Liberar más tiempo del personal de operaciones debería permitirles concentrarse en iniciativas más estratégicas dentro del negocio.
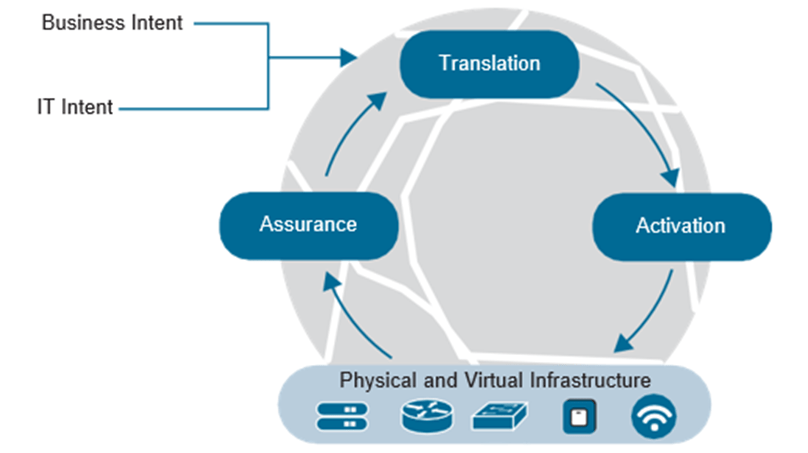
Las redes basadas en la intención (IBN, por sus siglas en inglés) están conquistando la industria de TI. El concepto gira en torno a significar la intención del negocio y traducir automáticamente esa intención en las tareas de red correspondientes apropiadas. Esta es una lógica circular en la que captura la intención del negocio y del personal de TI y luego traduce esa intención en las políticas apropiadas que se requieren para respaldar el negocio. Una vez creadas las políticas, el siguiente paso es orquestar la configuración de la infraestructura. Esto incluye tanto componentes físicos como virtuales. Esto luego inicia el paso final, que proporciona seguridad, información y visibilidad para garantizar que la red funcione correctamente. Debido a que en cierto sentido se trata de un bucle, la lógica utiliza la verificación continua y proporciona las acciones correctivas necesarias para reparar o mejorar el rendimiento de la red. La figura siguiente ilustra el modelo de red basado en la intención.
Los análisis y los conocimientos son absolutamente críticos para las redes de hoy. Los sistemas de administración de red (NMS) típicos no brindan la información necesaria para resolver problemas de manera rápida y eficiente. Son de naturaleza reactiva y no proporcionan el monitoreo predictivo y las alertas que requieren las organizaciones. Las trampas del Protocolo simple de administración de redes (SNMP) y los mensajes SYSLOG son valiosos, pero no se han utilizado tan bien como deberían. Las notificaciones reactivas significan que el problema o falla ya ocurrió y no evitan ningún impacto en el negocio. A menudo, hay falsos positivos o tantas alertas que es difícil determinar sobre qué información se debe actuar o ignorar por completo. Tradicionalmente, el flujo de trabajo de las operaciones de red ha sido similar al siguiente:
- Reciba una alerta o ticket de soporte técnico.
- Inicie sesión en los dispositivos para determinar qué sucedió.
- Dedique tiempo a la resolución de problemas.
- Resuelva el problema.
Se terminaron los días de buscar y buscar en los archivos de registro y depurar el tráfico para determinar cuál es el problema que ha causado una interrupción en la red. La cantidad de datos que se ejecutan a través de estas redes y deben clasificarse para solucionar un problema está aumentando exponencialmente. Esto está llevando a que la selección manual de la información para llegar a la causa raíz de un problema sea extremadamente más difícil que nunca. Las organizaciones confían en información relevante para lo que están buscando; de lo contrario, los datos son inútiles. Por ejemplo, si un usuario no pudo conectarse a la red inalámbrica el martes pasado a las 3 p. m. y los registros se sobrescriben o se llenan con información no útil, ¿cómo ayuda esto al personal de operaciones de la red a solucionar el problema en cuestión? no lo hace
Esto desperdicia tiempo, que es uno de los recursos más preciados para el personal de operaciones de red. La dicotomía de esto es usar análisis e información para ayudar a dirigir a los operadores de red al lugar correcto en el momento correcto para tomar la acción correcta. Esto es parte de lo que hace Cisco DNA Assurance como parte de las redes basadas en la intención.
El aislamiento de problemas es mucho más fácil dentro de una red basada en la intención porque toda la red actúa como un sensor que brinda información sobre las fallas que ocurren en la red. La red también tiene la capacidad de tener una visión holística de la red desde la perspectiva del cliente. Solo desde una perspectiva inalámbrica, esto puede proporcionar información como los motivos de la falla, el indicador de intensidad de la señal recibida (RSSI) e información de incorporación.
Una de las partes del proceso de solución de problemas que consume más tiempo es intentar replicar el problema. El problema mencionado anteriormente de que un usuario no pudo conectarse a la red el martes pasado a las 3 p.m. sería muy difícil de replicar. ¿Cómo podría alguien saber lo que posiblemente estaba pasando el martes pasado a las 3 p.m.? En realidad, la única forma tradicional de saber qué estaba pasando desde una perspectiva inalámbrica era tener capturas de paquetes constantes y analizadores de espectro en funcionamiento. Debido al costo, el espacio y el hecho de no saber dónde puede surgir el problema, este no es un enfoque práctico. ¿Qué pasaría si, en cambio, hubiera una solución que no solo pudiera actuar como un DVR para la red, sino que también usara información de telemetría de transmisión como NetFlow, SNMP y syslog y correlacionara los problemas para notificar al personal de operaciones de la red cuál era el problema, cuándo? sucedió—¿Incluso si sucedió en el pasado? Imagine la red proporcionando toda esta información automáticamente. Además, en lugar de tener
Usando puertos Switched Port Analyzer (SPAN) configurados en todo el campus con rastreadores de red conectados en todas partes con la esperanza de capturar el tráfico inalámbrico cuando hay un problema, imagine que los puntos de acceso inalámbrico podrían detectar la anomalía y ejecutar automáticamente una captura de paquetes localmente en el AP eso captaría el problema. Todos estos análisis
podría proporcionar pasos de remediación guiados sobre cómo solucionar el problema sin requerir que nadie busque todas las pistas para resolver el misterio. Afortunadamente, esa solución existe: Cisco DNA Assurance puede integrarse mediante API abiertas en muchas plataformas de emisión de tickets del servicio de asistencia, como ServiceNOW. La ventaja de esto es que cuando ocurre un problema en la red, Cisco DNA Assurance puede detectarlo automáticamente y crear un ticket de soporte técnico, agregar los detalles del problema al ticket, así como un enlace al problema en Assurance, junto con el pasos de remediación guiada. Eso significa que cuando el ingeniero de soporte de guardia recibe la llamada a las 2 a. m., ya tiene la información sobre cómo solucionar el problema. Pronto, la remediación automática estará disponible, por lo que la persona de guardia no tendrá que despertarse a las 2 a. m. cuando llegue el ticket. Este es el poder de Assurance y las redes basadas en la intención.
Arquitectura de red digital de Cisco
Cisco Digital Network Architecture (DNA) es una colección de diferentes soluciones que componen una arquitectura. Es la red basada en la intención de Cisco. Cisco DNA se compone de cuatro áreas clave: WAN, campus, centro de datos y borde de la nube. Cada área tiene sus propias soluciones Cisco que se integran entre sí: Cisco Software-Defined WAN (Cisco
SD-WAN), Acceso definido por software de Cisco (Cisco SD-Access), Infraestructura centrada en aplicaciones de Cisco (Cisco ACI) y Cisco Secure Agile Exchange (SAE). Cada área está construida con seguridad arraigada en cada solución. La Figura ilustra los pilares de Cisco DNA. En el centro, Cisco DNA está impulsado por la intención, informado por el contexto, aprendiendo constantemente y protegiendo constantemente. Esto es lo que traduce la intención comercial en política de red, brinda visibilidad constante de todos los patrones de tráfico y aprovecha el aprendizaje automático a escala para proporcionar una inteligencia cada vez mayor y permite que la red vea y prediga problemas y amenazas para que la empresa pueda responder más rápido.
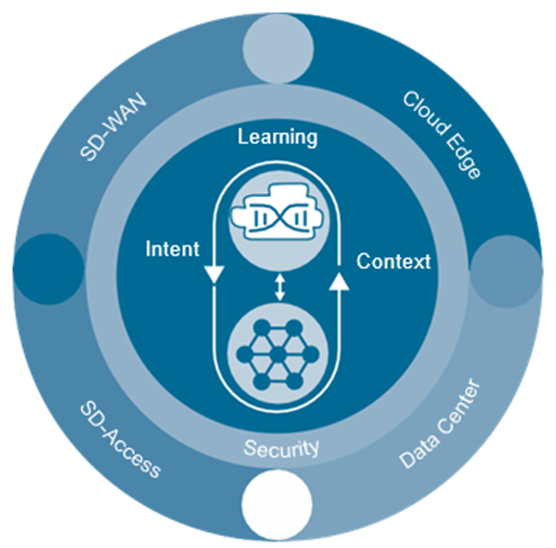
El mayor uso de servicios en la nube y dispositivos móviles está creando puntos ciegos de TI. Esta industria exige un nuevo enfoque holístico de la seguridad. La seguridad es el núcleo del ADN de Cisco. Cisco ofrece un ciclo de vida completo de soluciones locales y alojadas en la nube para maximizar la protección de las organizaciones. Debido a que Cisco puede concentrarse en todos los aspectos de la seguridad, esto reduce la complejidad al reducir a uno la cantidad de proveedores de seguridad necesarios para proteger el negocio. Cisco DNA puede convertir toda la red en un sensor para detectar tráfico malicioso y anomalías en el comportamiento. La Figura muestra las diferentes áreas de seguridad para las que Cisco ofrece soluciones.
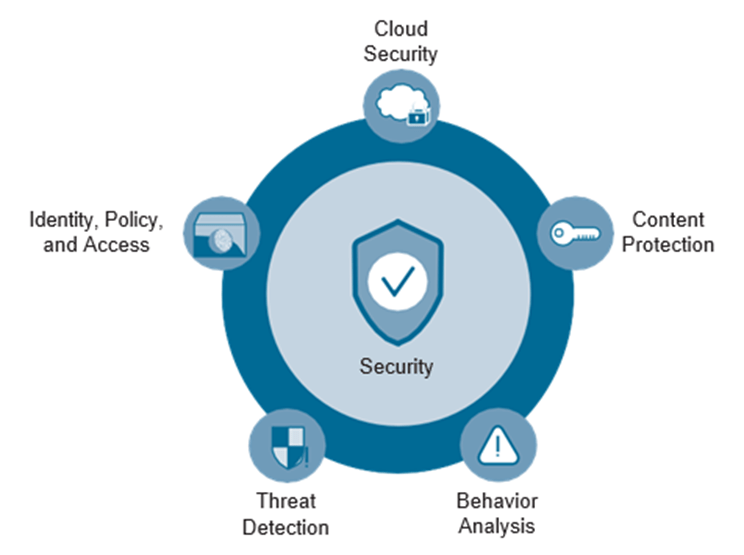
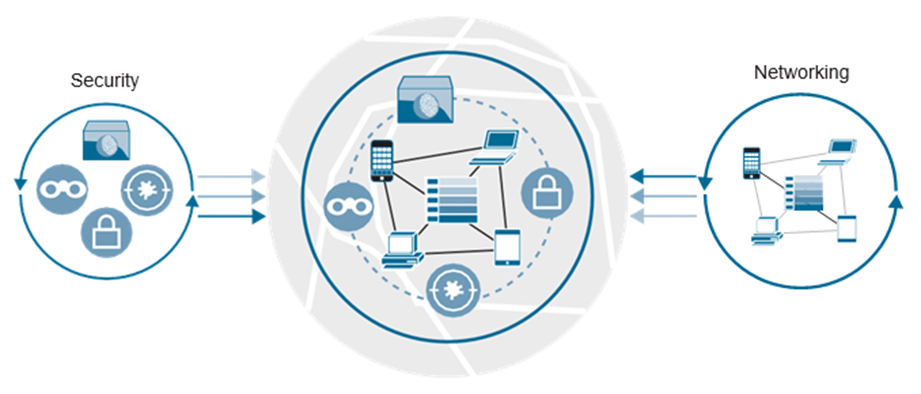
Cisco Stealthwatch puede establecer una línea base de la red y brindar detección de anomalías cuando algo cambia. Esto incluye incluso la detección de cambios en el tráfico o el comportamiento del usuario. Un gran ejemplo de esto es cuando un usuario generalmente usa una cantidad promedio de ancho de banda dentro de la red para realizar sus tareas laborales diarias. Si de repente el usuario comienza a descargar gigabytes de datos y enviarlos a otra máquina en otro país, Stealthwatch considera que esto es una anomalía. Esto no significa necesariamente que el usuario sea malicioso o esté robando datos de la empresa; podría ser que la máquina del usuario se haya visto comprometida y el malware esté atacando la red. En cualquier caso, Stealthwatch podría detectar esto e informar al personal de operaciones de TI para que tome medidas. La segmentación de red automatizada puede abordar este tipo de desafío para garantizar que los usuarios y las redes cumplan. Llevando esta innovación un paso más allá, los switches Cisco Catalyst de la serie 9000 tienen la capacidad de detectar malware y otras amenazas maliciosas dentro del tráfico cifrado. Esto se llama análisis de tráfico cifrado de Cisco (ETA). Esto es exclusivo de Cisco y es una de las formas más avanzadas de protección de seguridad disponibles en la actualidad. Combinando esto con toda la telemetría y visibilidad que la red puede proporcionar, reduce en gran medida el riesgo y el impacto potencial de las amenazas a la red. Es importante tener en cuenta que el poder de Cisco DNA es que todas estas tecnologías en todos estos pilares funcionan en conjunto. La seguridad está arraigada en todo lo que ofrece Cisco; no es una idea de último momento o algo que se monta en la parte superior de la red: la seguridad es la red. La Figura muestra el Cisco
postura sobre la seguridad y cómo encaja dentro del entorno de red. Ilustra que la seguridad es tan crítica como la propia red. Proporcionar la red más robusta que pueda aportar valor a la empresa y mejorar la experiencia de aplicación de los usuarios de forma segura y ágil es esencial para muchas organizaciones.
Soluciones del pasado a los problemas de hoy
A lo largo de los años, las demandas de la red han aumentado constantemente y la industria de TI se ha adaptado a estas demandas. Sin embargo, esto no significa que la industria se haya adaptado rápida o adecuadamente. Las redes solo existen para transportar aplicaciones y datos. Los métodos de cómo se han manejado estas aplicaciones y datos también han estado en constante cambio. Desde una perspectiva de diseño, los mecanismos implementados en la red dependen en última instancia del resultado que el negocio está tratando de lograr. Esto significa que los mecanismos no siempre son mejores prácticas o diseños validados. Las configuraciones de estos dispositivos a menudo son de naturaleza ad hoc y generalmente incluyen soluciones puntuales para los problemas que surgen en la red que deben abordarse.
Spanning-Tree y Redes Basadas en Capa 1
Una de las tecnologías más comunes que gana mucha notoriedad es Spanning Tree. Spanning Tree fue diseñado para evitar bucles en la red de Capa 2. Sin embargo, puede causar una gran cantidad de problemas en la red si no se ajusta y administra adecuadamente. Hay muchas configuraciones y técnicas de configuración para Spanning Tree, así como también múltiples versiones que proporcionan alguna variación de lo que el protocolo fue diseñado para hacer. La siguiente Tabla enumera las muchas versiones o sabores de Spanning Tree y sus abreviaturas asociadas.
| Tipo de Spanning Tree | Abreviación |
| Legacy Spanning Tree Protocol | STP |
| Per-VLAN Spanning Tree | PVST |
| Per-VLAN Spanning Tree Pluss | PVST+ |
| Rapid Spanning Tree Protocol | RSTP |
| Rapid Per-VLAN Spanning Tree Plus | RPVST+ |
| Multiple Spanning Tree | MST |
Spanning Tree se usa a menudo en arquitecturas de campus de tres niveles que dependen de las capas de distribución y acceso de la Capa 2, y el enrutamiento generalmente se realiza en el bloque de distribución. Esto depende completamente del diseño, por supuesto, pero este es el lugar habitual para Spanning Tree.
Los protocolos de redundancia de primer salto (FHRP) se utilizan para cada subred y se configuran para proporcionar información de puerta de enlace para las subredes locales y ayudar a enrutar el tráfico a su destino. Los siguientes son ejemplos de protocolos de redundancia de primer salto:
- Hot Standby Routing Protocol (HSRP)
- Virtual Router Redundancy Protocol (VRRP)
- Gateway Load Balancing Protocol (GLBP)
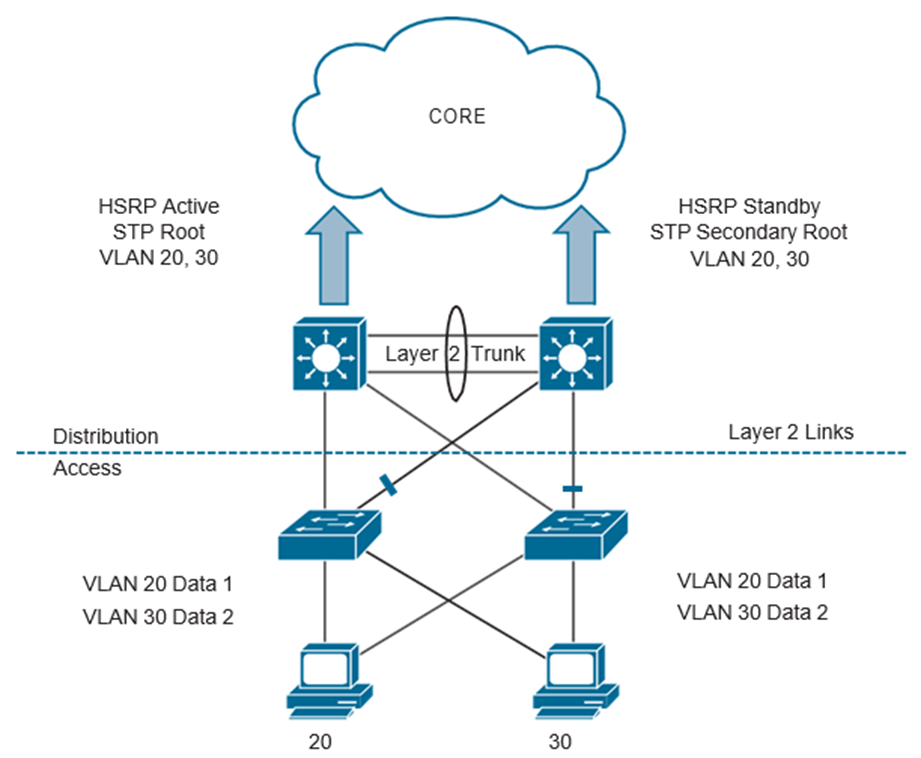
Antes de la llegada del acceso enrutado de Capa 3, Spanning Tree también se usaba principalmente en redes de Capa 2 que tenían VLAN ampliadas para admitir usuarios inalámbricos móviles. Esto se debió a que los usuarios inalámbricos requerían la capacidad de desplazarse por cualquier parte del campus y mantener el mismo identificador de conjunto de servicios (SSID), dirección IP y política de seguridad. Esto fue necesario debido a la dependencia de las direcciones IP y las VLAN para dictar qué política o lista de acceso se asoció a qué usuario con cable o inalámbrico. Sin embargo, había limitaciones inherentes de Spanning Tree, como solo poder usar la mitad del ancho de banda de un par de enlaces redundantes. Esto se debe a que la otra ruta está bloqueada. Sin embargo, hay muchas formas diferentes de manipular esto por VLAN o por instancia, pero este sigue siendo el caso de Spanning Tree. Otros inconvenientes son la posibilidad de problemas de inundación o enlaces bloqueados que causen una interrupción en la red. Esto afecta la continuidad del negocio e interrumpe a los usuarios, lo que dificulta que la red vuelva a estar en línea de manera rápida. Algunas interrupciones de Spanning Tree pueden durar horas o días si no se encuentra y soluciona el problema.
La siguiente figura ilustra un diseño típico de arquitectura de red de campus de tres niveles que aprovecha Spanning Tree y HSRP, y muestra que hay ciertos enlaces que no se pueden usar porque Spanning Tree bloquea los enlaces para evitar una ruta en bucle dentro de la red.
Con la llegada del acceso enrutado de Capa 3, Spanning Tree ya no es necesario para evitar loops porque ya no existe una red de Capa 2. Sin embargo, el acceso enrutado de Capa 3 introdujo otro conjunto de problemas que debían abordarse. Todavía queda el problema de la política de seguridad que depende del direccionamiento IP. Además, ahora que las VLAN no se extienden a través de la red mediante enlaces troncales, las redes inalámbricas tienen que cambiar la forma en que operan. Esto significa que los SSID inalámbricos deben asignarse a subredes, y si un usuario se mueve de un punto de acceso en un SSID y va al mismo SSID en otra área de la red en un punto de acceso diferente, es probable que su dirección IP cambie. Esto significa que tiene que haber otra lista de acceso en la nueva subred con la misma configuración que la lista de acceso en la subred anterior; de lo contrario, la política de seguridad del usuario cambiaría. Imagine la sobrecarga de tener que configurar múltiples listas de acceso en múltiples subredes. Así se configuraban tradicionalmente las redes. La cantidad de configuración manual, la posibilidad de errores de configuración y el tiempo perdido son solo algunas de las advertencias de este tipo de diseño de red. La siguiente Figura muestra una red de acceso enrutado de Capa 3.
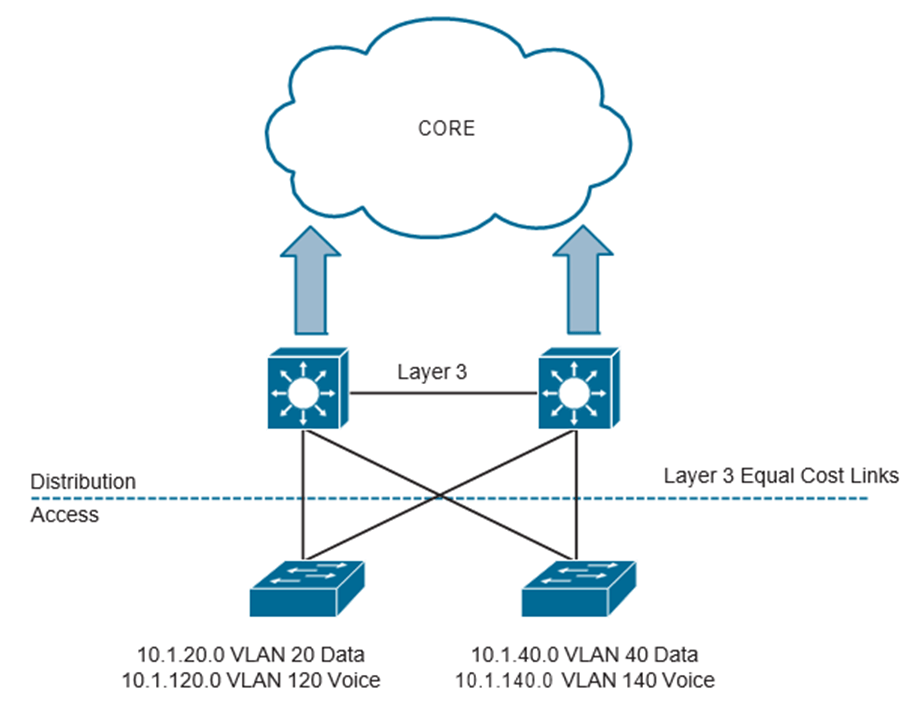
El acceso enrutado de capa 3 también es muy importante en el entorno del centro de datos. Esto se debe a todos los beneficios de pasar a un modelo de acceso enrutado de Capa 3 frente a una red de Capa 2. La siguiente es una lista de los beneficios de usar una red de acceso enrutado:
- Mayor disponibilidad
- Complejidad reducida
- Diseño simplificado
- Eliminación del árbol de expansion
Como se mencionó anteriormente en este Post, las aplicaciones de video interactivas y en tiempo real se están volviendo más comunes, y las organizaciones esperan que sus usuarios tengan la capacidad de conectarse desde cualquier lugar y en cualquier momento. La red del campus debe estar disponible en todo momento para respaldar este tipo de caso de negocios. El acceso enrutado aprovecha los enlaces punto a punto, lo que no solo reduce la cantidad de tiempo que lleva recuperarse de una falla de enlace directo, sino que simplifica el diseño al confiar solo en un protocolo de enrutamiento dinámico (frente a las complejidades de Capa 2, Spanning Tree y protocolos de enrutamiento de capa 3). Junto con todos los enlaces en el entorno que ahora están activos y reenvían tráfico, hay una gran ganancia en el ancho de banda y una detección de fallas más rápida con enlaces punto a punto en comparación con la Capa 2. La industria exige redes que incluyan ultrarrápido, bajo -latencia, enlaces de gran ancho de banda que están siempre disponibles y que pueden escalar para satisfacer las demandas de las organizaciones que los utilizan. La siguiente Figura ilustra la diferencia entre los diseños de campus basados en la Capa 2 y la Capa 3.
Introducción a Multidominio
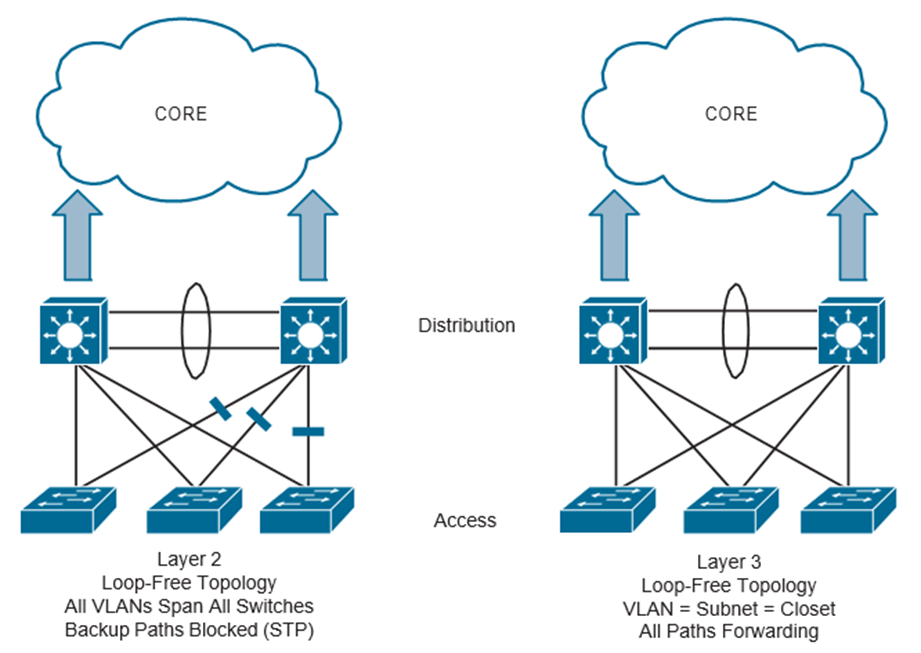
Una tendencia común que está surgiendo en la industria de TI es generar y almacenar datos en muchas áreas de la red. Tradicionalmente, la mayoría de los datos de una empresa se almacenaban en un centro de datos centralizado. Con la afluencia de acceso de invitados, dispositivos móviles, BYOD e IoT, los datos ahora se generan de forma remota y distribuida. En respuesta, la industria está cambiando de centros de datos a múltiples centros de datos. Dicho esto, la conectividad simple, segura y de alta disponibilidad es imprescindible para permitir una mejor experiencia de usuario y aplicación. La otra gran pieza del multidominio es tener una política transparente que pueda abarcar estos múltiples centros de datos. Un ejemplo de esto es la política que se extiende desde el entorno del campus a través de la WAN hasta el centro de datos y de regreso al campus. Esto proporciona coherencia y un comportamiento determinista en los múltiples dominios. La siguiente Figura ilustra un ejemplo de alto nivel de la política de uso compartido entre una sucursal del campus y un centro de datos que ejecuta la Infraestructura centrada en aplicaciones (ACI) de Cisco.
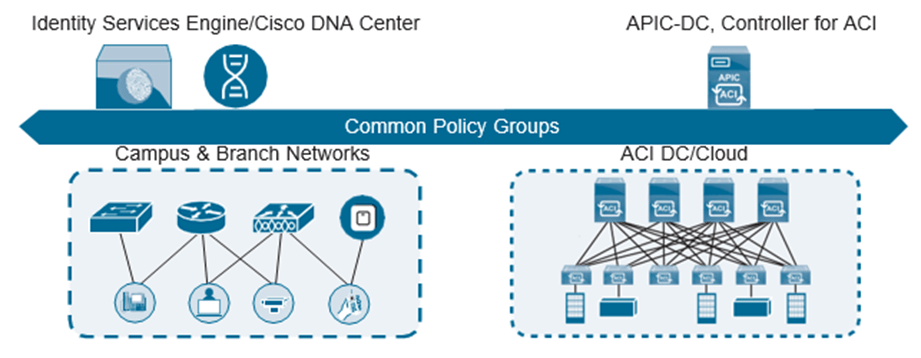
En futuras evoluciones de multidominio, la política común se extenderá desde el campus a través del entorno de WAN definida por software de Cisco (SD-WAN) hasta Cisco ACI que se ejecuta en el centro de datos y de regreso al campus, proporcionando una política de extremo a extremo y gestión en los tres dominios. Esto proporcionará la capacidad de aprovechar cosas como los acuerdos de nivel de servicio (SLA) de la aplicación desde el centro de datos hasta la WAN y viceversa, asegurando que las aplicaciones funcionen al máximo de su capacidad en toda la red. También aliviará la tensión en la WAN y brindará una mejor experiencia de usuario al usar las aplicaciones. La siguiente Figura muestra un ejemplo de alto nivel de cómo podría verse esto desde una perspectiva de topología general.
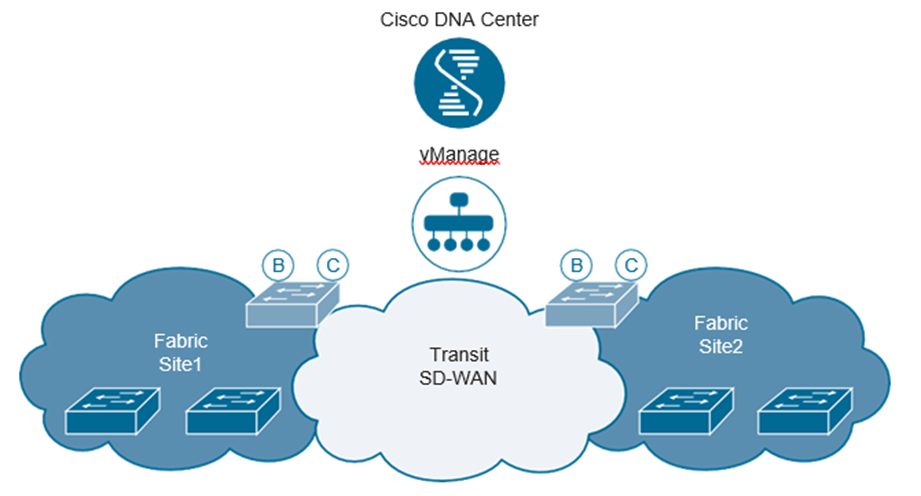
Multidominio ofrece la capacidad de hacer que la red funcione como un sistema holístico, como se mencionó anteriormente en este Post. Esto lleva las redes basadas en la intención al siguiente nivel al tomar políticas en todos los dominios para una experiencia de aplicación perfecta. Esto también implementa seguridad en todas partes y proporciona granularidad completa en términos de control y operaciones. Mirando el multidominio desde otro aspecto, la solución de acceso definido por software de Cisco también puede compartir políticas con la solución SD-WAN de Cisco. Esto es poderoso porque las políticas que controlan la seguridad, la segmentación y el rendimiento de las aplicaciones se pueden aplicar en todo el entorno de la red. Esto significa que la experiencia del usuario y de la aplicación es congruente en toda la LAN y WAN del campus. Unir ambos dominios es lo que ofrece las capacidades para proteger las aplicaciones y garantizar que se cumplan los resultados empresariales por los que se esfuerzan las organizaciones. La Figura 1-13 ilustra un diseño multidominio de alto nivel con Cisco DNA Center, Cisco vManage, Cisco SD-Access y Cisco SD-WAN.
Tendencias y adopción de la nube
La adopción de la nube ha tomado por asalto a la industria. A lo largo de los años, la dependencia de la computación en la nube ha crecido significativamente, comenzando con la música, las películas y el almacenamiento y pasando a SaaS e IaaS. Hoy en día, hay muchos aspectos de las organizaciones que se ejecutan en la nube, como el desarrollo de aplicaciones, el control de calidad y la producción. Para complicar aún más las cosas, las empresas confían en múltiples proveedores de nube para operar su negocio, lo que da como resultado conjuntos únicos de políticas, requisitos de capacidad de almacenamiento y habilidades operativas generales por proveedor. Las empresas están luchando con cosas como la sombra de TI y las aplicaciones de puerta trasera en su entorno. Shadow IT es cuando las líneas de negocio (LoB) van a los proveedores de la nube por su cuenta, sin ningún conocimiento ni guía de los departamentos de TI, y activan aplicaciones bajo demanda en la nube. Esto causa grandes preocupaciones desde una perspectiva de seguridad y privacidad. Además, la posible pérdida de información confidencial o propiedad intelectual podría dañar la marca y la reputación de la empresa. Los riesgos son significativos.
Además, las aplicaciones en la nube, ya sean aplicaciones de producción legítimas o aplicaciones que se encuentran actualmente en desarrollo, aún requieren ciertos niveles de prioridad y tratamiento para garantizar que las aplicaciones se entreguen correctamente a los usuarios que las consumen. Aquí es donde algunas de las capacidades de la red de campus de próxima generación pueden ayudar a garantizar que las aplicaciones se traten adecuadamente y que la experiencia de los usuarios sea adecuada. La Figura ilustra la demanda en el campus LAN y WAN y cómo las aplicaciones en la nube se están volviendo críticas para las operaciones del negocio. La red del campus tiene la responsabilidad compartida de garantizar que las aplicaciones funcionen de la mejor manera posible y brinden una experiencia de usuario excepcional. La red del campus también tiene que compartir la carga de seguridad para asegurarse de que los usuarios apropiados accedan a las aplicaciones y compartan información en primer lugar. Aquí es donde tener una buena política de segmentación y seguridad es primordial.
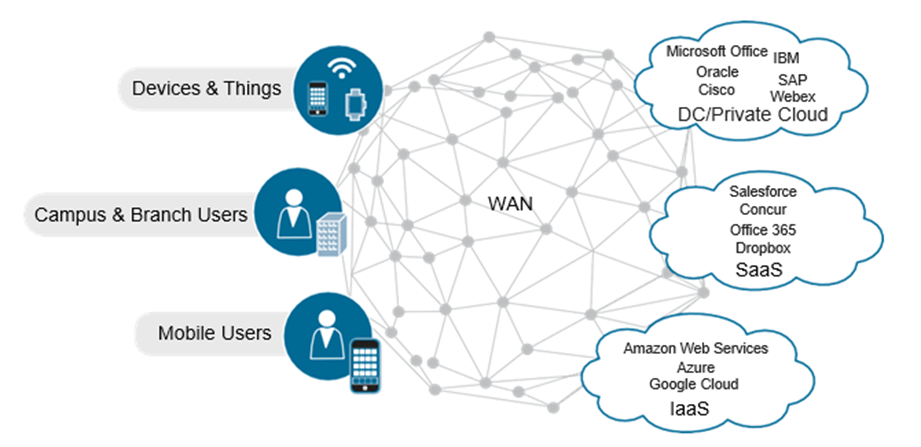
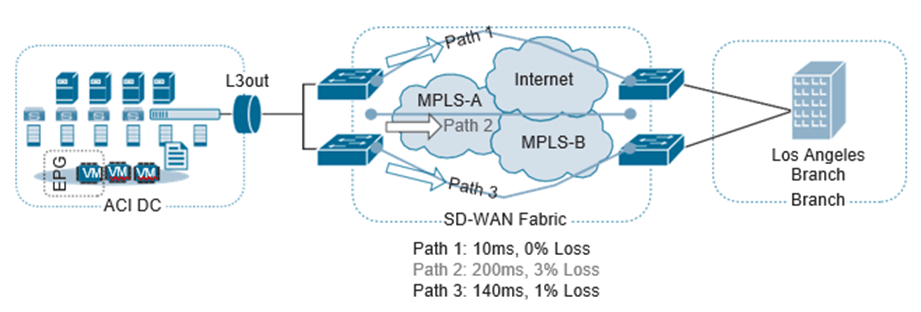
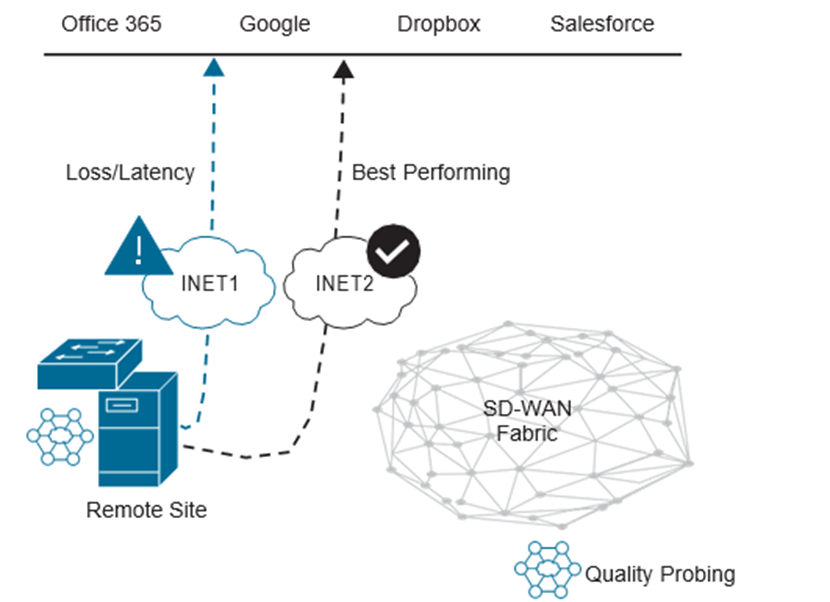
La mayor parte del ancho de banda que consumen las aplicaciones afecta más al entorno WAN que a la LAN del campus. Esto se debe a que los enlaces WAN tienen una cantidad de ancho de banda más finita en comparación con los enlaces de ancho de banda de alta velocidad que se ven en un entorno de campus. Tener acceso directo a Internet en una sucursal puede ayudar a aliviar parte de esta presión. Al poder detectar el rendimiento de la aplicación a través de uno o más circuitos de acceso directo a Internet, los Routers de sucursal pueden elegir la ruta de mejor rendimiento en función de los parámetros específicos de la aplicación. Esto ayuda a compensar el transporte WAN de bajo ancho de banda.
Si uno de los enlaces a la aplicación en la nube falla o tiene una degradación en el rendimiento, la aplicación puede conmutar por error automáticamente a otro enlace directo de Internet. Este proceso está completamente automatizado y no requiere la interacción del personal de operaciones de la red. La siguiente figura se muestra este escenario con múltiples enlaces de acceso directo a Internet.


Deja un comentario