Metodología de resolución de problemas
Las responsabilidades de un administrador de red se reducen a estos objetivos esenciales: maximizar el rendimiento y la disponibilidad mientras se minimizan los costos y el tiempo de reparación.
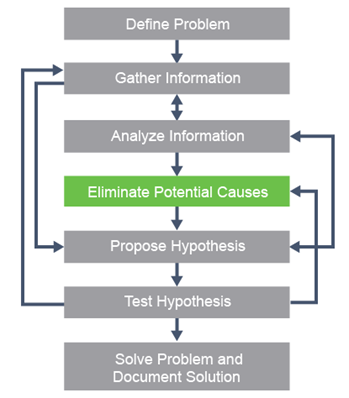
Un marco para la resolución de problemas, basado en el método científico, se describe como un proceso de seis pasos:
- Paso 1. Definir el problema.
- Paso 2. Reúna información.
- Paso 3. Analizar información y eliminar posibilidades.
- Paso 4. Plantear una hipótesis.
- Paso 5. Probar la hipótesis.
- Paso 6. Interpretar los resultados y, si es necesario, generar una nueva hipótesis.
El primer paso (descripción del problema) se logra cuando un usuario informa un problema. La descripción inicial del problema tiende a ser demasiado general; por ejemplo, «¡Internet no funciona!»
Por lo tanto, la respuesta inicial de un solucionador de problemas debería ser (Paso 2) recopilar más información y utilizarla para (Paso 3) eliminar posibilidades. Determine los síntomas hablando con el usuario, observando personalmente o consultando sistemas de gestión como NetFlow, Syslog y monitores SNMP. La eliminación de posibilidades depende de la experiencia y de la comprensión de la tecnología y la topología.
Cuando tenga una descripción adecuada del problema, formule una hipótesis (Paso 4). Una hipótesis es una posible explicación cuyos síntomas serían similares a las observaciones. Debería sugerir una forma de probarse o refutarse (Paso 5). Por ejemplo, si sospecha que la conexión WAN no funciona, observar el estado de la interfaz o hacer ping a un dispositivo remoto puede comprobar esa idea.
Los resultados de la prueba apoyan o refutan una teoría (Paso 6). El resultado de una sola prueba no puede probar una teoría; simplemente respaldarla. Por ejemplo, se podría utilizar ping para probar una conexión WAN. Un tiempo de espera de ping no puede, por sí solo, considerarse definitivo. Es posible que el objetivo esté apagado o que tenga un firewall que elimine ICMP. Los resultados de las pruebas deben confirmarse mediante varias líneas de evidencia diferentes. Si las pruebas contradicen la hipótesis, comience de nuevo con una nueva teoría.
Una vez que se acepta una hipótesis como explicación razonable, se toman medidas para solucionar el problema. Por supuesto, cualquier acción es otro tipo de prueba. Si no soluciona el problema, simplemente desarrolle una nueva hipótesis y repita el proceso.
Solución de problemas estructurada
El término resolución estructurada de problemas describe cualquier forma sistemática de recopilar información, formular una hipótesis y probarla. En un enfoque estructurado, cada prueba fallida descarta toda una clase de posibilidades y, con suerte, sugiere la siguiente hipótesis. Un enfoque no estructurado (aleatorio) suele llevar mucho más tiempo y es menos probable que tenga éxito.
Se han utilizado con éxito varias técnicas, cuya característica común es un enfoque riguroso y reflexivo que recopila y analiza datos.
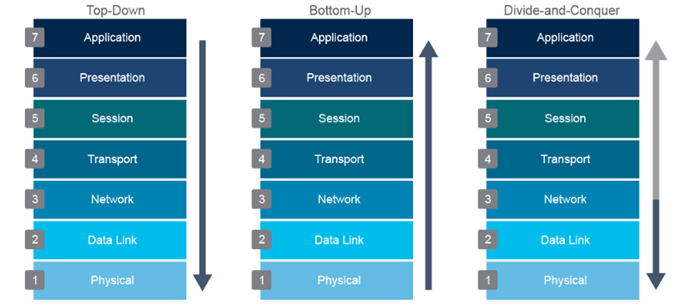
Algunas de ellas se describen centrándose en las tres primeras técnicas en el venerable modelo OSI, como se muestra a continuación:
- De abajo hacia arriba: comience con la capa física OSI y avance.
- De arriba hacia abajo: comience en la capa de aplicación OSI y profundice.
- Divide y vencerás: comienza en la capa de red y sigue la evidencia, desarrollando pruebas específicas de cada hipótesis.
| 7. Aplicación |
| 6. Presentación |
| 5. Sesión |
| 4. Transporte |
| 3. Red |
| 2. Enlace de Datos |
| 1. Física |
La siguiente tabla describe cómo se pueden utilizar algunos comandos de IOS o PC disponibles para respaldar un enfoque de resolución de problemas basado en OSI.
| Capa del modelo OSI | Herramienta |
| Aplicación | Nslookup (desde PC, probarDNS) |
| Transporte | Telnet (probar puertos TCP) Ttcp (puede probar puertos UDP) |
| Red | show ip interface show ip route ping and traceroute |
| Enlace de datos | show interface show ip arp |
| Física | show inventory show environment show memory show process De forma visual inspeccione de forma visual medios y conectores |
Un segundo conjunto de técnicas de resolución de problemas se centra más en el entorno en el que existe el dispositivo. Estos enfoques consideran el hardware, la interconectividad y los estándares:
- Siga el camino: considere la “perspectiva de los paquetes” y examine los dispositivos y procesos que se encuentran moviéndose a través de la red.
- Detectar diferencias: compare la configuración con una versión anterior o un dispositivo similar. Herramientas como Diff y WinDiff facilitan esta comparación.
- Mueva el problema: intercambie componentes para ver si el problema permanece en el dispositivo o se mueve con el componente. Una versión de esto es un reinicio estratégico para ver si eso resuelve el problema.
- Qué cambió (post hoc ergo proptor hoc): determine si algo cambió justo antes de que se desarrollara el problema. La teoría aquí es que el momento implica causalidad. A veces esto da una pista, pero muchas cosas suceden simultáneamente en las redes cada segundo. Úselo con precaución: este método de solución de problemas puede proporcionar fácilmente una pista falsa.
- Disparar desde la cadera: Finalmente, todos los solucionadores de problemas se dedican a adivinar de vez en cuando. Aunque rara vez se reconoce como un enfoque riguroso, a veces la experiencia y la intuición conducen a soluciones muy rápidas. Esto puede resultar increíblemente impresionante cuando funciona; el truco consiste en no dejar que esto se convierta en una serie de puñaladas aleatorias cuando no funciona.
No existe un único “mejor método”, aunque un técnico puede encontrar uno más adecuado para un problema determinado. Es una buena idea estar familiarizado con cada técnica y cambiar los enfoques según sea necesario.
¡Qué hacer cuando nada funciona!
En ocasiones, los problemas parecen desafiar toda explicación. Aquí hay algunas ideas, sin ningún orden en particular, que le permitirán continuar trabajando en el problema y superar un bloqueo:
- Prueba de suposiciones: por lo general, los problemas parecen “raros” porque los síntomas no se comprenden adecuadamente. Si llega a un callejón sin salida, una forma de reiniciar es volver a la descripción original y probar las suposiciones para asegurarse de que la descripción sea precisa.
- Limpiar: cuando era niño, cuando perdía mi juguete favorito y no podía encontrarlo, mi madre decía: “Apuesto a que lo encontrarás si limpias tu habitación”. La mayoría de las veces tenía razón y el mismo principio se aplica a las redes. Las configuraciones acumulan basura: ACL que ya no se utilizan, vecinos o protocolos de enrutamiento abandonados, interfaces desconectadas. La red física también recolecta basura, como armarios de cableado desordenados. Cuando estés perplejo, ¡limpia! A veces la solución surge mientras trabajas.
- Tómese un descanso: la resolución de problemas es un proceso creativo. A medida que aumenta la presión y cubres el mismo terreno una y otra vez, los solucionadores de problemas pierden la perspectiva y están dispuestos a intentar cualquier cosa para que el dolor desaparezca. Si llega al punto de frustrarse, pídale a un compañero de equipo que se haga cargo por un momento y se vaya. Cuando dejas que tu mente divague, ¡a veces la respuesta te viene a la cabeza!
- Obtenga ayuda: ¡Los solucionadores de problemas pueden desarrollar fácilmente una mentalidad de piloto de combate y perder la perspectiva! Pídale a otro operador de red que haga una lluvia de ideas, pregúntele al servidor o a la gente de la aplicación qué ven, pídale a su proveedor de servicios que revise si se trata de una conexión WAN y, mejor aún, su organización probablemente le pague a Cisco mucho dinero por un contrato SmartNet. ¡Así que llama a TAC!
Herramientas de solución de problemas
La mayoría de los administradores de red tienen una variedad de herramientas en su bolsa de herramientas. Algunas de las herramientas básicas incluyen un historial de configuración, registros de dispositivos y documentación. A medida que crece el número de dispositivos mantenidos, las herramientas que recopilan datos sobre el rendimiento de la red y las herramientas que recopilan problemas de los usuarios se vuelven cada vez más importantes.
Dos de las herramientas más básicas son ping y traceroute.
Ping prueba la conectividad y se usa con tanta frecuencia que incluso los usuarios finales están ligeramente familiarizados con él. Una respuesta de ping muestra que existe una ruta de trabajo entre dos puntos finales. Los sistemas finales a veces tienen firewalls que impiden la respuesta, pero generalmente el ping es una primera prueba razonable de conectividad de red, como se muestra en el siguiente ejemplo.
R1# ping 10.186.1.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.186.1.1, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 8/9/12 ms
Los signos de exclamación muestran una respuesta, pero hay mucha información además de la parte más obvia. Primero, preste atención al patrón de la respuesta.
La alternancia de éxito y fracaso (!.!.!) es una señal clásica de un problema de equilibrio de carga, donde una ruta tiene éxito y la otra falla. En segundo lugar, considere el tiempo de respuesta. Muchas aplicaciones dependen de una respuesta rápida. La voz, por ejemplo, supone un tiempo de ida y vuelta inferior a 150 ms. El tiempo de respuesta también puede indicarle al solucionador de problemas de utilización. Si el tiempo de respuesta es mucho mayor de lo habitual, eso podría indicar una gran carga de tráfico y colas. Si nota que los tiempos mínimo y máximo varían mucho, esto también podría ser una señal de que hay cola debido a una carga pesada.
Sin embargo, Ping puede hacer mucho más que esa simple prueba. El modo privilegiado admite un ping extendido que permite controlar todos los aspectos del ping. Esto abre muchas más pruebas que se pueden realizar con el humilde comando.
El ejemplo siguiente se muestra un ping extendido. Observe que el comando ping (sin un destino especificado) se ingresa en modo privilegiado. Envía cinco pings de 100 bytes, luego cinco de 200 bytes y continúa con pings de 1500 bytes. El bit DF (no fragmentar) está configurado. Se podría utilizar un ping similar si sospecha que un enlace intermedio no admite el mismo tamaño de MTU que el origen y destino. Se encuentra una explicación más detallada del comando después del ejemplo.
R1# ping
Protocol [ip]:
Target IP address: 10.186.1.1
Repeat count [5]:
Datagram size [100]:
Timeout in seconds [2]:
Extended commands [n]: y
Source address or interface: loopback0
Type of service [0]:
Set DF bit in IP header? [no]: y
Validate reply data? [no]:
Data pattern [0xABCD]:
Loose, Strict, Record, Timestamp, Verbose[none]: Sweep range of sizes [n]: y
Sweep min size [36]: 100
Sweep max size [18024]: 1500
Sweep interval [1]: 100
Type escape sequence to abort.
Sending 75, [100..1500]-byte ICMP Echos to 10.186.1.1, timeout is 2 seconds:
Packet sent with a source address of 10.1.1.1 Packet sent with the DF bit set
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!
!!!!!
Success rate is 100 percent (75/75), round-trip min/avg/max = 8/10/12 ms
Recuerde que los valores predeterminados se muestran entre corchetes. Seleccionar todos los valores predeterminados es similar a un ping normal.
A veces, las pruebas implican hacer ping repetidamente (por ejemplo, cuando cree que una interfaz se mueve hacia arriba y hacia abajo). Se puede utilizar un ping extendido con un recuento de repeticiones de 99999 para probar interactivamente la red durante un período de tiempo.
Los pings se pueden configurar para diferentes tamaños de paquetes a través de la variable Tamaño del datagrama. El enrutador puede automatizar las pruebas de una variedad de tamaños. Para hacerlo, use los comandos extendidos y elija barrer una variedad de tamaños.
Si se le pide a un enrutador que reenvíe un paquete que es más grande que la MTU del enlace de transmisión, normalmente divide el paquete en partes más pequeñas. Configurar el bit DF indica a los enrutadores receptores que descarten el tráfico en lugar de fragmentarlo.
Usar paquetes de diferentes tamaños y configurar el bit DF permite probar MTU. Cuando se alcanza el límite de MTU, se eliminan todos los pings posteriores.
Otra técnica de prueba beneficiosa es cambiar la interfaz de origen. Los pings normalmente provienen de la interfaz de transmisión. El uso de una interfaz interna como fuente muestra que el dispositivo receptor y los enrutadores intermedios entienden cómo enrutar de regreso a ese prefijo.
Una última idea es probar diferentes configuraciones de Tipo de Servicio. Muchas redes ahora transmiten voz, video y datos priorizados. La voz suele estar configurada en ToS 5, por lo que hacer ping usando ToS 5 permite echar un vistazo a cómo están funcionando las configuraciones de QoS.
Al igual que ping, existe una versión extendida de traceroute. Tiene algunas de las mismas capacidades, con otra capacidad de prueba importante. Traceroute en IOS usa UDP y el traceroute extendido permite configurar el puerto UDP. Esto se puede emplear para probar el rendimiento de aplicaciones que utilizan UDP, como la voz. Esto es importante cuando se intenta diagnosticar los efectos de los cortafuegos y las listas de acceso.
En el ejemplo de abajo muestra un traceroute extendido. La única opción especificada en el ejemplo siguiente se muestra el como es utilizar el puerto UDP 16000.
R1# traceroute
Protocol [ip]:
Target IP address: 10.200.1.1
Source address: Numeric display [n]:
Timeout in seconds [3]:
Probe count [3]:
Minimum Time to Live [1]:
Maximum Time to Live [30]:
Port Number [33434]: 16000
Loose, Strict, Record, Timestamp, Verbose[none]: Type escape sequence to abort.
Tracing the route to 10.200.1.1
De la misma manera que se puede probar la conectividad del puerto UDP con traceroute, se puede usar telnet para probar los puertos TCP. Telnet no ofrece muchas opciones, pero cambiando el puerto de destino se pueden probar diferentes servicios de red.
Este ejemplo muestra que el correo electrónico y el servidor web responden en los puertos apropiados.
R1# telnet www.example.com 25
Translating “www.example.com”...domain server (10.1.2.2) [OK] Trying www.example.com (172.16.0.25, 25)... Open
220 www.example.com ESMTP Postfix
R1# telnet www.example.com 80
<ctrl-c>
HTTP/1.1 400 Bad Request
Diagnóstico de hardware
Los comandos examinados hasta ahora han solucionado problemas de red, pero a veces el problema está dentro del dispositivo IOS. Varios comandos describen el estado funcional de un dispositivo IOS.
Si se sospecha del hardware de la red, un buen lugar para comenzar a solucionar problemas es comprender el entorno externo. El comando show environment all muestra información sobre la temperatura dentro del dispositivo y el estado de las fuentes de alimentación, como se muestra en el ejemplo de abajo Especialmente cuando la resolución de problemas se realiza de forma remota, es fácil olvidarse de la energía y el aire acondicionado, pero los problemas en cualquiera de las áreas pueden provocar un mal funcionamiento del dispositivo.
R1# show environment all
Power Supplies:
Power Supply 1 is AC Power Supply. Unit is on. Power Supply 2 is AC Power Supply. Unit is on.
Temperature readings:
NPE Inlet measured at 25C/77F NPE Outlet measured at 27C/80F I/O Cont Inlet measured at 25C/77F I/O Cont Outlet measured at 28C/82F CPU Die measured at 43C/109F
Voltage readings:
+3.30 V measured at +3.30 V
+1.50 V measured at +1.49 V
+2.50 V measured at +2.50 V
+1.80 V measured at +1.79 V
+1.20 V measured at +1.20 V
VDD_CPU measured at +1.28 V
VDD_MEM measured at +2.50 V
VTT measured at +1.25 V
+3.45 V measured at +3.43 V
-11.95 measured at -12.17 V
+5.15 V measured at +4.96 V
+12.15 V measured at +12.18 V
Envm stats saved 0 time(s) since reload
La falta de memoria también puede provocar un problema de red. El comando show memory muestra el estado de la memoria en un dispositivo, como se muestra en el Ejemplo 1-14. Concéntrese en la columna Gratis para determinar si es suficiente
disponible. Una señal de problemas de memoria son los mensajes %SYS-2-MALLOCFAIL.
R1# show memory
Head Total(b) Used(b) Free(b) Lowest(b) Largest(b)
Processor 6319860 818832732 74864300 743968432 742841100 727580236
I/O 38000000 67108864 11964260 55144604 55137712 54643068
Transient 37000000 16777216 58244 16718972 16226680 16718696
…
Los problemas de hardware también se manifiestan en las interfaces. El comando show controllers puede revelar cierta información sobre la interfaz; las interfaces seriales en particular reportan cosas como información del cable aquí. El comando show interfaces (que se muestra en el ejemplo) muestra una gran cantidad de información sobre el estado de la interfaz. En particular, preste atención a cuatro medidas:
- Input queue drops: significa que el enrutador tenía más tráfico del que podía procesar. Una cierta cantidad de caídas es excusable, pero las caídas podrían estar relacionadas con la sobresaturación de la CPU. Vuelva a verificar el procesador con el comando show processs cpu.
- Output queue drops: normalmente significa que la línea está congestionada.
- Input errors: muestra errores dúplex, problemas de interfaz y errores CRC.
- Output errors: normalmente relacionados con problemas de impresión dúplex.
R1# show interface
FastEthernet0/0 is up, line protocol is up
Hardware is i82543 (Livengood), address is 000a.f3f7.9808 (bia 000a.f3f7.9808)
Description: enter port # Internet address is 10.100.1.1/16
MTU 1500 bytes, BW 100000 Kbit/sec, DLY 100 usec, reliability 255/255, txload 32/255, rxload 14/255
Encapsulation 802.1Q Virtual LAN, Vlan ID 1., loopback not set Keepalive set (10 sec)
Full-duplex, 100Mb/s, 100BaseTX/FX ARP type: ARPA, ARP Timeout 04:00:00
Last input 00:00:00, output 00:00:00, output hang never Last clearing of “show interface” counters never
Input queue: 0/75/0/0 (size/max/drops/flushes); Total output drops: 0
Queueing strategy: fifo
Output queue: 0/40 (size/max)
5 minute input rate 5517000 bits/sec, 2571 packets/sec
5 minute output rate 12927000 bits/sec, 2550 packets/sec 1326060749 packets input, 711066620 bytes
Received 45468700 broadcasts, 0 runts, 0 giants, 0 throttles
148 input errors, 0 CRC, 0 frame, 0 overrun, 148 ignored
0 watchdog
0 input packets with dribble condition detected 1191821108 packets output, 2981100223 bytes, 0 underruns
2 output errors, 0 collisions, 4 interface resets 5634739 unknown protocol drops
0 babbles, 0 late collision, 0 deferred
2 lost carrier, 0 no carrier
0 output buffer failures, 0 output buffers swapped out

